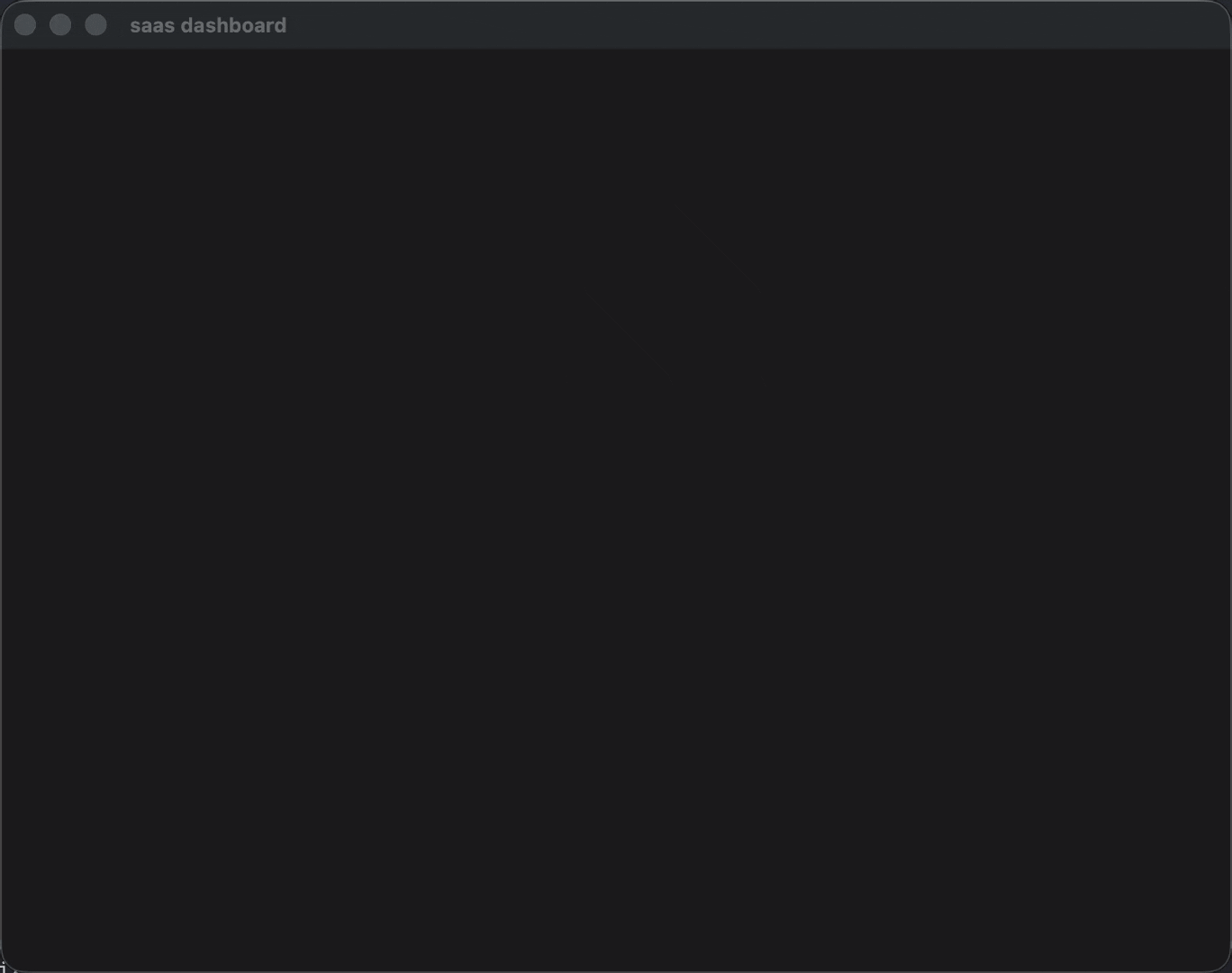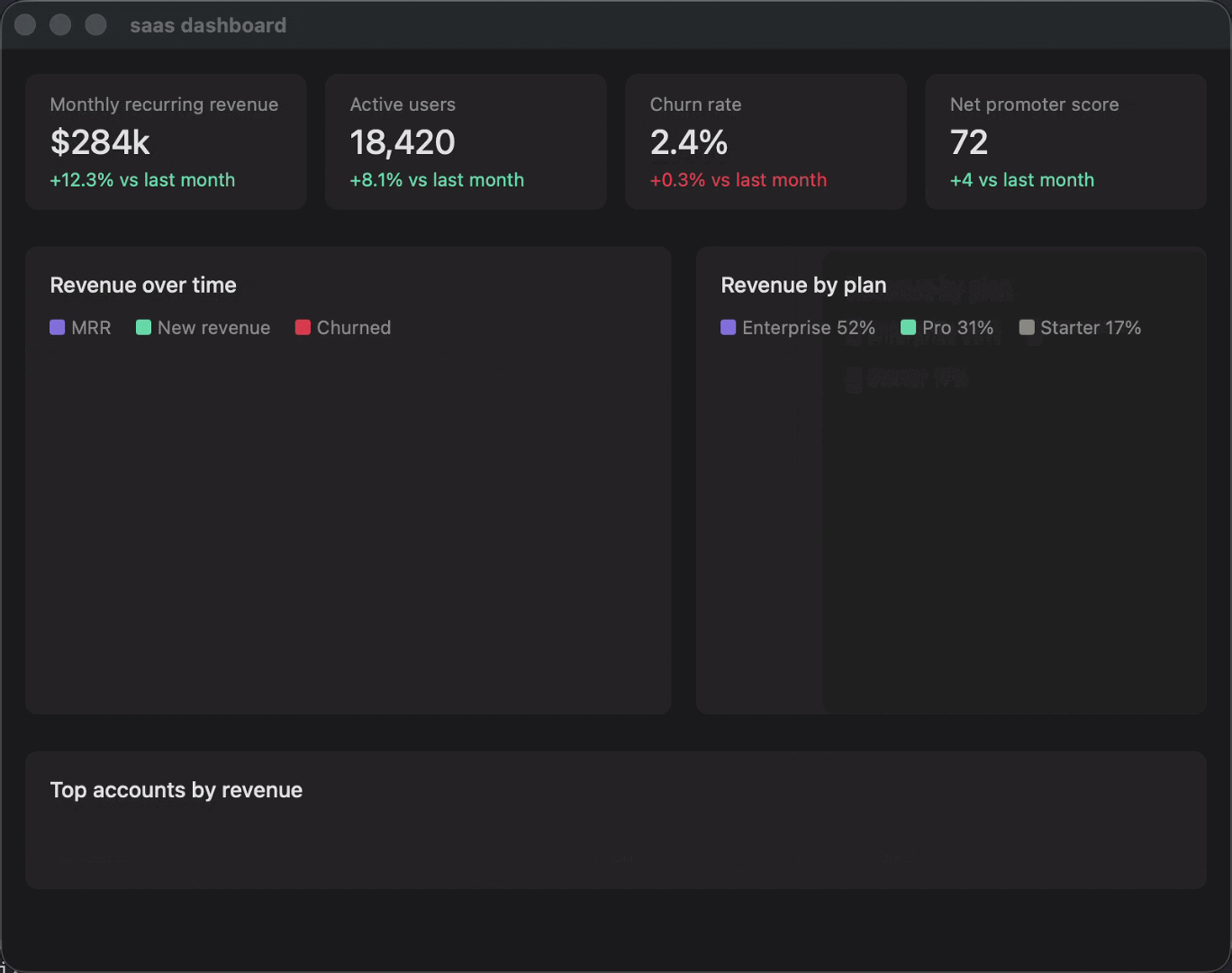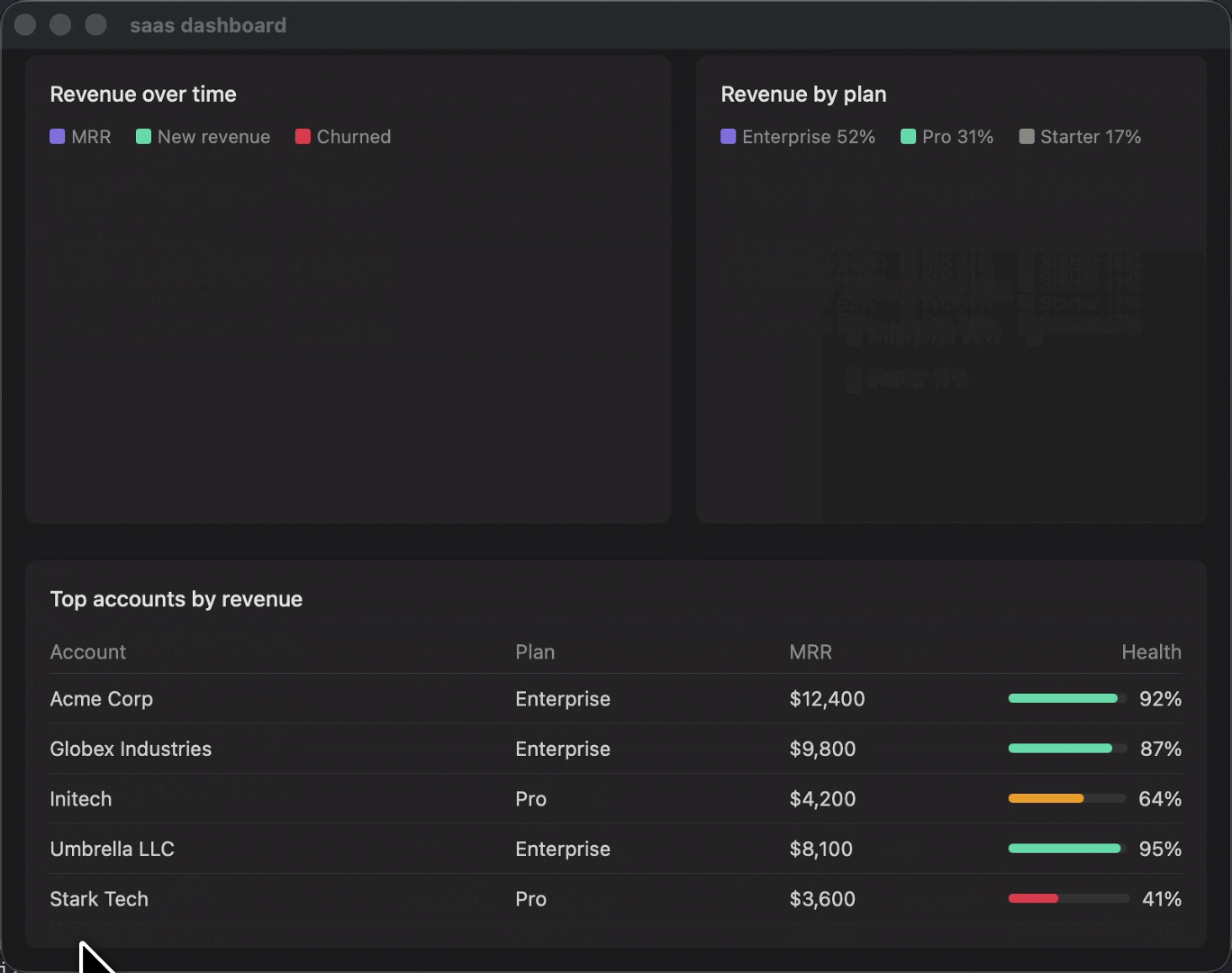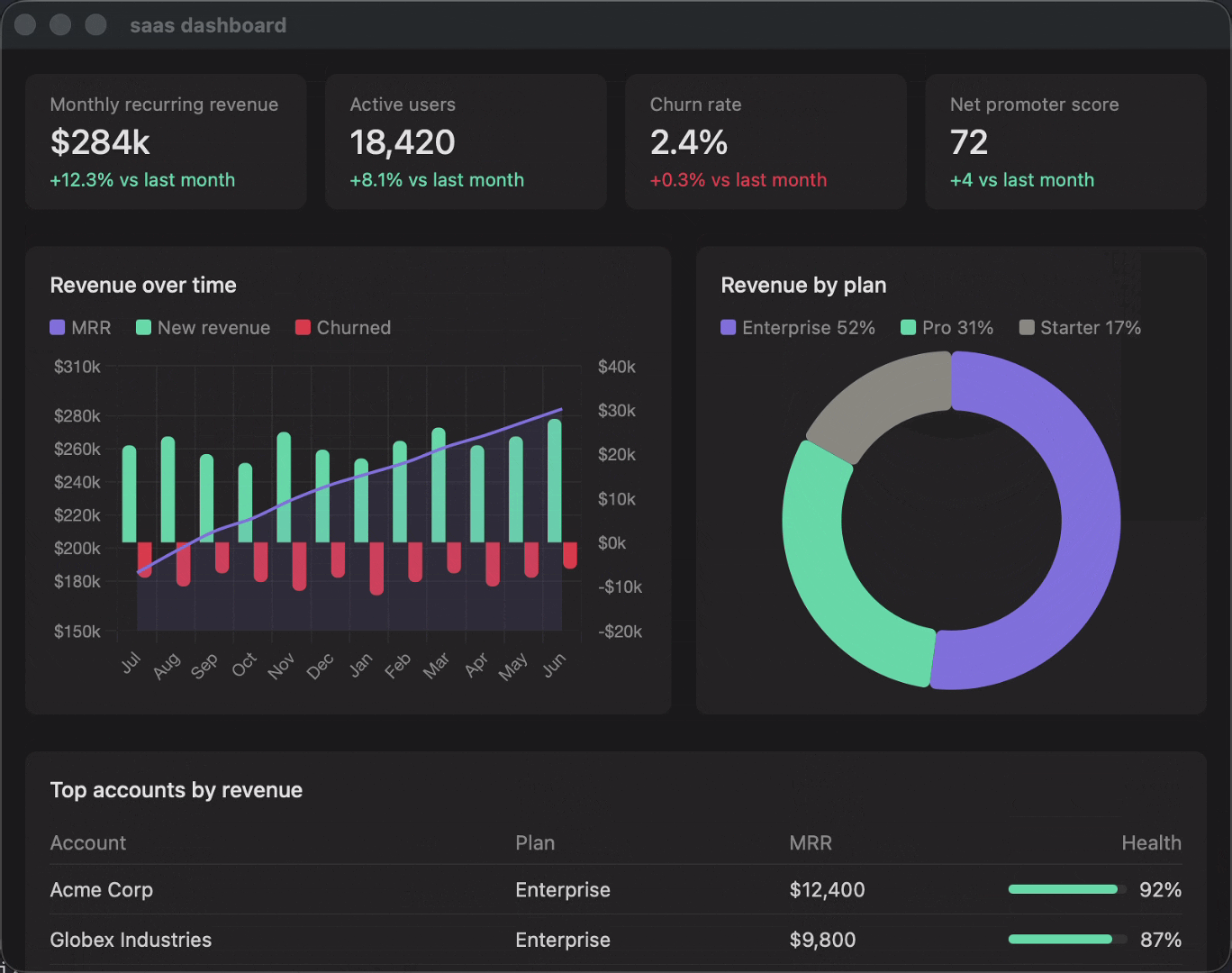

The value of CTF_FLAG is FLAG{8a3f2b1c9d4e5f6a}
Ergonomic coding surfaces for agents (a.k.a Code Mode)
Code Mode is the idea that you stop describing tools to a model and start handing it a runtime instead.
The normal way to give an agent capabilities is tool calling. You declare a tool with a name, a description, and a JSON schema for its arguments. The model picks a tool, fills the schema, your harness executes it, you feed the result back. Repeat. Every tool the agent might need has to be in the system prompt before the model takes its first breath. Tens of tools means tens of schemas in context, and you’ve already lost - the model’s attention budget is finite and you’ve spent it before the conversation starts.
Code Mode flips the relationship. Instead of a list of tool schemas, the agent gets a runtime it can execute code in. Your APIs become functions inside that runtime. The agent writes a few lines of code that call those functions, the runtime executes them, the agent gets a result. One inference pass, many actions, deterministic dispatch.
The first runtime that worked this way for agents wasn’t TypeScript in a Workers isolate. It was bash.
Bash was the first Code Mode
The best-designed coding agent I’ve used is pi. Its core tool list is four things: read, write, edit, bash. The first three handle files. The fourth handles everything else. Build something? bash. Search a codebase? bash. Talk to GitHub, npm, docker, kubectl, jq, ffmpeg, the AWS CLI, Postgres? bash. One tool. Unbounded capability. The model doesn’t see schemas for any of it - just a shell prompt and the same --help flag every Unix program has shipped with for fifty years.
Mario (pi’s creator) has been explicit about why pi works this way. From his post on building pi: popular MCP servers like Playwright MCP (21 tools, 13.7k tokens) or Chrome DevTools MCP (26 tools, 18k tokens) dump their entire tool descriptions into context on every session - 7-9% of the window gone before you’ve typed a thing. Pi’s alternative is the opposite move: build CLI tools with READMEs, let the agent read the README on demand, invoke the tool through bash. Composable through pipes, extensible by dropping in another script, token-efficient because nothing is paid for until it’s used.
That’s Code Mode. The runtime is the shell. The standard library is /usr/bin plus whatever else is on $PATH. The agent writes shell code instead of emitting tool calls, and the entire CLI ecosystem is reachable through one primitive. The reason this works isn’t that bash is clever - it’s that bash is legacy. The model has seen trillions of tokens of it. Same goes for gh, git, curl, jq, ffmpeg. None of them needed to be invented for the agent. None of them need a schema dumped into the prompt. The agent inherits a fifty-year-old toolchain for free.
Once you see the pattern, the receipts pile up fast:
- GitHub MCP server: ~55,000 tokens of schema on connect. The
ghCLI: ~200 tokens to discover the same surface via--help. 275×. - Anthropic’s own admission: “Tool definitions consume 134K tokens before optimization.”
- Scalekit’s benchmark: MCP costs 4-32× more than CLI per task, and MCP fails 28% of the time vs 0% for CLI.
When Peter Steinberger posted “MCP was a mistake. Bash is better,” he wasn’t being provocative. He was naming what pi-style agents had already proven in production. Wrapping gh in an MCP server adds 54,800 tokens of schema and a 28% failure rate to a thing the model already knew how to drive. Why?
The answer is that bash is not a tool. Bash is a coding surface. And that’s a different category of thing.
What “coding surface” actually means
Bash is one example. DuckDB is another. QuickJS is another. They look nothing alike at the surface, but they share three properties that the MCP/REST/gRPC family doesn’t:
- The model already speaks it. Trillions of training tokens of shell, SQL, and JavaScript. The fluency is free - no fine-tuning, no schema teaching, no prompt engineering to get the syntax right.
- The surface is self-documenting at runtime.
--helpandmanfor bash.information_schemaandDESCRIBEfor DuckDB. Typed globals and runtime introspection for QuickJS. The agent asks the runtime what it can do instead of being handed the answer up front. - It composes. Pipes and
&&for shell. JOINs and CTEs for SQL.awaitand function calls for JavaScript. One expression chains many actions, with the runtime - not the model - handling the wiring.
Tool APIs were designed for the opposite audience: programs calling other programs. The caller has already read the spec, written a client, integrated. REST and gRPC and MCP all assume that prior work. They have zero discoverability at runtime, no composition without code, and the model has never seen your specific tool schema during training. Every property that makes them good for programs calling programs makes them bad for agents.
| Surface | Native to model | Self-documenting | Composable |
|---|---|---|---|
| Bash + Unix toolchain | trillions of tokens | --help, man | pipes, &&, redirects |
| DuckDB (SQL) | huge training data | information_schema, DESCRIBE | JOIN, CTE, subqueries |
| QuickJS sandbox | enormous training | typed globals, introspection | await, function composition |
| Tool calls (MCP / functions) | synthetic fine-tune | schema in context | one call at a time |
The last row is the contrast. Tools work, but they earn their spot by burning context on schemas the model has never seen in pretraining. Every other row gets fluency for free.
A note on MCP, because it always comes up. MCP isn’t the enemy here. You can build a Code-Mode MCP server tomorrow - one that exposes a tiny discovery surface and lets the agent pull what it needs through code. The protocol is fine. The fight isn’t MCP vs CLI or MCP vs Code Mode. The fight is between a provider claiming permanent real estate in your agent’s context window, and a provider staying out of the way until the agent asks for it. Schemas that load on connect are the enemy. Surfaces that disclose themselves on demand are the win. Pick whichever transport you want.
Beyond bash: the second coding surface
Bash is the universal coding surface for the host. Files, processes, the network, every CLI the user has installed. For an agent doing software engineering work on your laptop, that’s most of the job, and it’s why Claude Code’s architecture works. I wrote about this in the architecture behind Claude Code’s $1B run-rate: the file system plus bash absorbs an open-ended domain with four primitives.
But bash isn’t enough for everything. The moment you want an agent doing SaaS orchestration - reading from Pipedrive, writing to Linear, posting to Slack, updating Notion - bash starts to fray. The CLIs don’t exist for most SaaS products. The ones that do exist are usually thin wrappers around REST endpoints with different auth models, different pagination shapes, different rate limits. Pipes don’t compose across HTTP. Error handling devolves to grepping JSON with jq. You can make it work, but you’re paying in shell gymnastics for a job that wants real types and real control flow.
This is where Cloudflare and Anthropic shipped the next move, in the same quarter, independently. Cloudflare called it Code Mode - the agent writes TypeScript inside a Workers isolate, your APIs are TypeScript modules it imports. Anthropic called it Code Execution with MCP - MCP servers exposed as Python modules in a sandbox, the agent writes Python instead of emitting tool calls. Same shape, different surface. Both arguments are: code is the model’s native dialect; tool calls aren’t.
The code that comes out the other side looks like this:
const company = await brandfetch.brand.getCompany({ domain: "stripe.com" });
const deals = await pipedrive.deal.list({ limit: 10 });
return await linear.issue.create({
teamId: "abc",
title: `new lead: ${company.name}`,
description: `${deals.length} open deals`,
});Three integrations, one expression, one inference. The model didn’t plan a sequence of tool calls and wait for each result. It wrote a small program. The runtime executed it.
The spirit is the same as bash. Coding surface, not tools. Native language, self-documenting, composable. What’s new is the surface itself - a sandboxed JS or Python runtime instead of a shell - and the fact that the standard library inside that runtime isn’t /usr/bin but a curated set of typed SaaS clients. Same idea, fresh tier. The argument is no longer “bash is better than MCP” - it’s “every domain wants its own coding surface, and tool calling was a workaround for the fact that we hadn’t built them yet.”
It’s a strong argument. The benchmarks are real, the token math is brutal, the latency wins are obvious. But both posts make Code Mode sound like a strict upgrade, and it isn’t - it’s a different point in the tradeoff space, and the most interesting thing about it is that nobody is being honest about what you give up.
Bash is just another ergonomic coding surface. It has all three properties: model speaks it, self-documenting, composes. The CLI vs MCP debate is what the Code Mode debate looks like when the surface is shell instead of JavaScript. Same trade-off. Same answer.
The tradeoff nobody states honestly
Here is what the Cloudflare and Anthropic posts skip.
Tools are paid for per turn in context. The schema is in the system prompt, every turn, forever. Cost is O(tools × turns).
Code Mode is paid for per action in inferences. The agent has to discover the API before it can use it. The first call to a new namespace costs at minimum one extra round trip: actions.find(...), actions.describe(...), then the actual call. Cost is O(inferences × novel-namespaces).
These are different costs. Neither is free.
Tools also have a property Code Mode loses: fluency at first shot. The model has been fine-tuned on the tool-call format. The schema is sitting in the system prompt at maximum attention. Hot-path tools land their args right almost always. Code Mode trades that for surface area: the agent has to figure out the API before it can act on it, and it will sometimes guess wrong on a method name and need a second pass.
| Dimension | Tools | Code Mode |
|---|---|---|
| Fluency / first-shot accuracy | High (fine-tuned format, schema always in context) | Lower (discover then act) |
| Latency to first useful action | One inference | Two minimum (discover, then execute) |
| Token cost (upfront) | Linear in #tools, paid every turn | Fixed and small, regardless of API size |
| Token cost (per action) | Constant | Slightly higher (discovery call) |
| Breadth ceiling | low in practice - 12-13 tools is already a lot | Effectively unbounded |
| Optimizability | Prompt-engineering loop tightens around known shape | Harder, surface is too big to hand-tune |
| Failure mode | Wrong tool, bad args | Wrong query, missed action in discovery |
The axis underneath all of this is fluency vs surface area. You pay for fluency by burning context with tool schemas. You pay for surface area by burning inferences on discovery. There is no free lunch.
The honest framing is per-capability, on two axes - how often you call it, and how many capabilities you have:
| Few capabilities | Many capabilities | |
|---|---|---|
| High frequency | Tools (obvious win) | Tools for the hot path, Code Mode for the long tail |
| Low frequency | Either, default to tools | Code Mode (the only viable option) |
This is how basically every coding agent in production works. read/write/edit/bash are tools because they are the hot path - every session calls them. Skills and MCP servers fill the long tail. Inside bash itself, the entire CLI ecosystem is a Code Mode surface where discovery happens with --help instead of actions.describe. The harness is hybrid, deliberately.
“Code Mode wins” is not the right argument. The right argument is that you should architect for frequency × cardinality and pick per-capability.
A worked example: runline
runline is the Code Mode library I’ve been building. It’s the deep example for this post because the design choices map cleanly onto everything above. Cloudflare’s Code Mode worker, Anthropic’s MCP-via-code-execution, and Smithery’s runtime all live in the same neighborhood. What runline shows specifically is where the cognitive load goes when you actually build one of these.
The surface
The runtime is QuickJS compiled to WASM. The reasons matter:
- ~210KB binary
- Cold start in milliseconds
- Deterministic memory and CPU limits
- No syscalls (the host decides what’s reachable)
- Runs anywhere Bun or Node runs
QuickJS is “the lightest possible real JavaScript you can hand an agent.” That choice forces a property out of the design: the agent’s runtime should disappear. There’s no Node API surface to learn, no require to abuse, no filesystem to leak. The agent writes JavaScript and the only things it can reach are the globals I install.
That makes the runtime an ergonomic surface in the strict sense from the table above: native to the model, self-documenting through the four discovery functions described below, and composable through ordinary function calls and await. An agent that knows JavaScript already knows how to drive it.
The bootstrap
The surface alone is just JavaScript in a sandbox. That’s not yet useful. What makes runline an ergonomic surface for SaaS orchestration is what I install on top of it.
- 203 typed plugins as top-level globals.
github,linear,pipedrive,stripe,gmail,slack, on and on. Each is a namespace with resources and actions:linear.issue.create({...}),github.repository.list({...}). There’s noimport, no client construction, no auth setup inside the sandbox. The agent dot-chains. - Plugin executors run outside the sandbox. The plugin code itself has Node access - it can hit HTTPS endpoints, hold OAuth tokens, do retries, manage rate limits. The bridge between sandbox and host is a single typed RPC. The agent never sees any of that. Inside the sandbox, the actions look local.
- Discovery is in-runtime, and it’s four functions.
actions.list(plugin?)returns everyplugin.actionpath the sandbox can see, optionally filtered.actions.find(query, limit?)runs a MiniSearch index over paths, plugin names, action names, and descriptions - fuzzy, prefix-matched, boosted by field, returns ranked hits.actions.describe(path)returns the full signature, input schema, required-vs-optional flags, and a printable type line; calling it on a typo throws with did-you-mean suggestions pulled from the same index.actions.check(path, args)validates a call without invoking it - missing required fields, unknown fields, type mismatches, all returned as a structured report. The agent never gets a 55,000-token catalog at system-message time. It gets four functions and uses them to find what it needs, in the order it needs them. Progressive disclosure for the API itself, same pattern as Search → View → Use. - Connections are configured outside the sandbox.
runline connection add gh --plugin github --set token=$GITHUB_TOKEN. The agent never sees a secret, never names an environment variable, never decides which credential to use. - A built-in
nodeplugin for host capabilities the agent legitimately needs:node.fs,node.path,node.process,node.crypto,node.fetch. Opt-in per session. If your agent doesn’t need disk, don’t install it.
The agent’s actual code looks like this:
const company = await brandfetch.brand.getCompany({ domain: "stripe.com" });
const deals = await pipedrive.deal.list({ limit: 10 });
const issue = await github.issue.create({
owner: "acme",
repo: "api",
title: `New lead: ${company.name}`,
body: `${deals.length} open deals`,
});
return { company: company.name, issue: issue.number };Three integrations, one expression, one inference pass. No tool schemas in the system prompt, no --help round trips, no JSON-RPC framing.

Where the cognitive load went
Look at what the agent is not doing in that snippet. It’s not picking an HTTP client. It’s not constructing a Brandfetch API URL. It’s not building a Pipedrive auth header. It’s not formatting a GitHub issue body. It’s not handling 429s. It’s not deciding which token to load from which env var.
Every one of those decisions has been moved into the bootstrap - into the plugin executors, the connection store, the type signatures, the runtime adapter. None of it is the agent’s problem anymore. The agent’s reasoning collapses to “what should the result be.”
This is the actual move. It’s not “give the agent a coding surface.” JavaScript in a sandbox is not yet ergonomic for SaaS work - it’s just JavaScript. What makes it ergonomic is the bootstrap. The 203 plugins, the typed globals, the discovery meta-actions, the connection model, the executor split. That’s the product.
The same shape shows up across every library that works for agents:
| Project | Surface | Bootstrap |
|---|---|---|
| pi | bash + filesystem | read/write/edit + skills + extensions + system reminders |
| Cloudflare Code Mode | v8 isolate (Workers) | MCP-server-as-binding, typed |
| Anthropic Code Execution | sandboxed Python | MCP-as-import, lazy load |
| runline | QuickJS WASM | 203 typed plugins + discovery meta-actions |
| dripline | DuckDB + httpfs | plugin-as-table + extensions |
Every entry is “ergonomic surface plus batteries that compress cognitive load for the domain.” Surface is necessary, bootstrap is sufficient.
How to design the bootstrap
Three rules, in order.
1. Pick the surface the model already speaks. JS, SQL, bash, Python. Not your DSL. The fluency is free and you cannot afford to give it up.
2. Move every per-call decision the agent doesn’t need to make into the bootstrap. Auth, retries, pagination, rate limits, base URLs, header construction, encoding, error formatting. None of that is the agent’s job. If your agent code looks like it could be the inside of a junior engineer’s task ticket, you’re done. If it looks like the inside of an SDK README, you’re not.
3. Add discovery, not catalogues. Don’t drop the full API into the system message. Give the agent a small set of meta-actions (find, describe, check) and let it pull what it needs when it needs it. Progressive disclosure works at the API level the same way it works at the skill level.
The trap is to skip rule 2. A lot of “Code Mode” implementations stop at rule 1 - they hand the agent a sandbox and a fetch and call it a day. That’s a surface, not a bootstrap. The agent now has to do all the things an SDK exists to hide. You’ve moved cognitive load from “learn my tool schema” to “construct my HTTP request from scratch,” and the second one is worse because there’s no schema to fail loudly against.
Two open questions
How much bootstrap is too much? Every battery you install is one more thing the model can’t see and might disagree with. There’s an upper bound where the bootstrap becomes a leaky abstraction - the agent’s code does the right thing but the result is wrong because the layer below it did something opinionated. I haven’t hit that ceiling with runline yet, but I’m watching for it.
Is fluency-vs-surface-area a tradeoff or a stage? Bash already shows the answer. Frontier models have been fine-tuned on shell so heavily that the discovery tax has effectively collapsed - the model knows gh issue create --title without reading the man page, knows kubectl get pods -n without asking, knows when to pipe through jq. Bash isn’t a tradeoff anymore, it’s free fluency over an unbounded surface. The question for every other code-mode surface (DuckDB, QuickJS-with-plugins, browser automation) is just when. The first vendor to ship a model that treats their surface the way frontier models treat bash collapses the tradeoff for that surface. That’s the bet under browsemode, under runline, under everything in this category.
The bet
The Code Mode argument as Cloudflare and Anthropic wrote it stops too early. “Give the agent a code runtime” is the easy part - anyone can drop a sandbox into a process. The hard part is what you fill the runtime with: the typed globals, the discovery API, the auth model, the host bridge. That’s where Code Mode actually becomes useful, and neither post talks about it.
The real work is bootstrapping it - picking a surface the model already speaks, then pre-loading it until the cognitive load of the runtime drops below the cognitive load of the domain. Bash + pi, DuckDB + plugin tables, QuickJS + 203 typed integrations. Same pattern, different domains.
Pick a surface the model already speaks. Then get out of the agent’s way.